Daprによる分散アプリケーションのリトライ処理について
お仕事でプリセールスをして極めてミッションクリティカルな業務システムに携わっているため、お客様やSIパートナー様といっしょに「絶対に止まらないシステム」について検討することが多くあります。インフラの可用性については、すでに多く議論されているのですが、いわゆるクラウドネイティブアプリケーションの場合は、分散システムを考慮したアプリケーションアーキテクチャについて検討する必要があります。
これはクラウドに限った話ではないのですが、分散システムでは一過性の障害をなくすことはできません。なので分散システムにおいて「SLAを100%にするぞ!」ではなく、「障害が起こっても素早く回復させる」「一部の障害を系全体に伝播させない」というようなアプローチのほうが筋が良いといえるでしょう。
参考: Azure で回復性があるアプリケーションを実現するためのエラー処理
クラウドネイティブなアプリケーションは、クラウドベンダーが提供するサービス/ユーザが個別で開発するシステムサービスを組み合わせて開発することで、クラウドの持ち味であるアジリティやスケーラビリティを活かすことができますが、次のような分散システムが本質的に持つ技術的課題もあります。
- サービス間の呼び出し
- サービス間での状態共有
- システムの監視
- シークレットの管理
- 障害部分のみ切り離してサービスを継続させる
Microsoftは、クラウドネイティブなシステムにおいて分散処理を実装するランタイムである「Dapr(Distributed Application Runtime)」をオープンソースとして開発し、CNCFに寄贈しました。このDaprは上記の課題をアプリケーションランタイムで解決しようというアプローチをとっています。
Daprが提供する機能
Daprはライブラリのようにアプリケーションに組み込むのではなく、Dapr自身がコンテナあるいはプロセスとして実行され、それをサービスからHTTP/gRPC API経由で呼び出して利用するビルディングブロックとして実現されているのが特徴です。
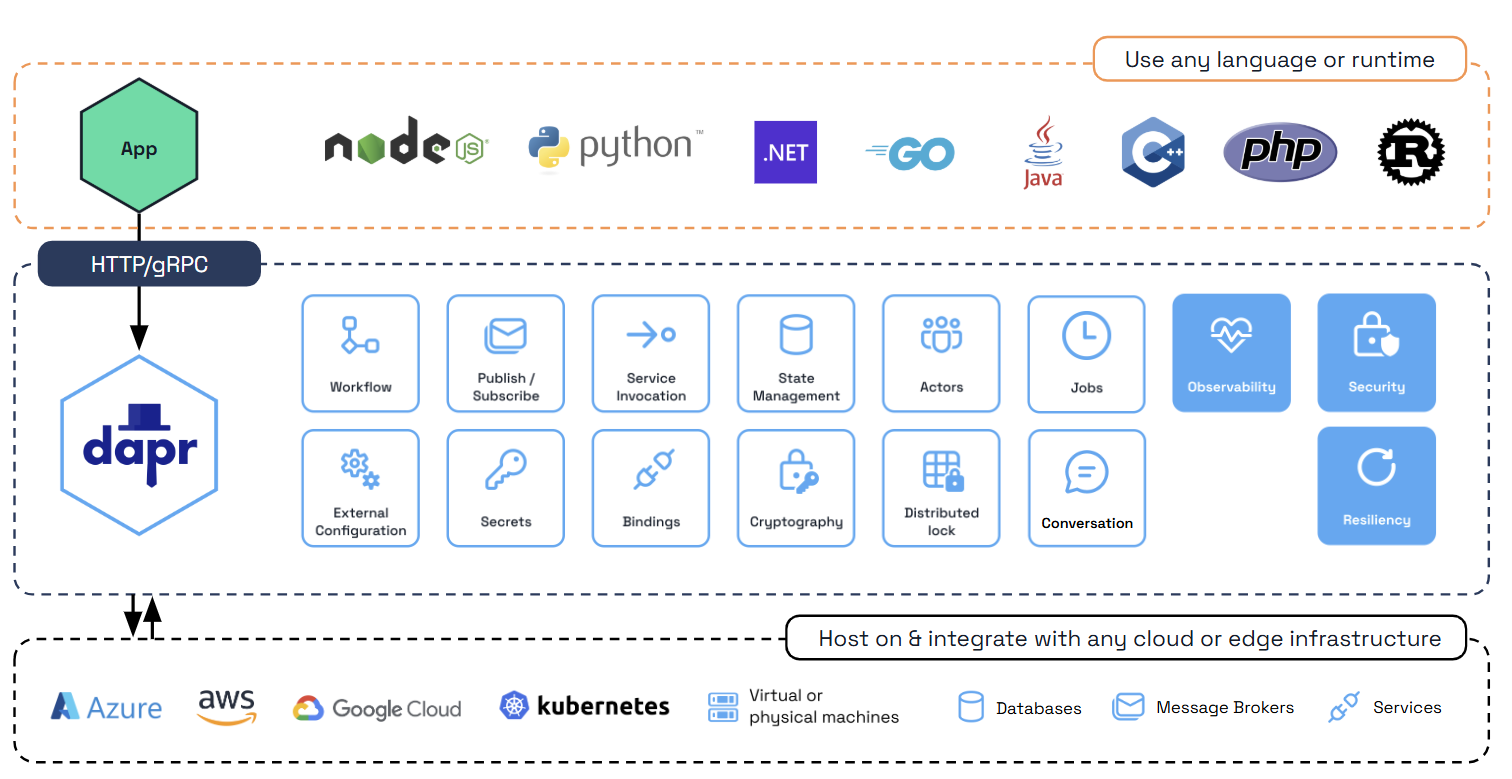
Service Invocation リトライ、分散トレースなどのマイクロサービスに不可欠な機能をサポートするサービス間通信機能
State management キー/バリュー形式の状態管理 状態を保管するコンポーネントとしてRedis/CosmosDB/MySQLなどがある
Publish & subscribe messaging publish/Subscribe形式のメッセージング機能
Bindings データベースやキュー、ファイルシステムなどにイベントを送受信する機能
Actors アクターズパターンに関連する機能
Observability 各種メトリックス、ログ、トレース機能
Secrets management 秘匿情報の管理機能 AWS Secrets Manager/GCP Secrets Manager/Azure Key Vaultなどと連携可能
Configuration アプリケーションの構成管理
Daprのアーキテクチャ
Daprは、HTTPおよびgRPC APIを、コンテナーまたはプロセスとしてサイドカーアーキテクチャとして公開し、アプリケーションコードにDaprランタイムコードを含める必要はありません。

といわれても、何が嬉しいのかちょっとピンとこないですよね。なにをかくそう、私もです。
この記事では、Daprの数ある機能のうち
- Service Invocation
- State management
の2つについてコードを書きながら検証したことをまとめました。
システムアーキテクチャを考える
というわけで、とあるエンタープライズ企業向けにTodoアプリを開発する例で考えます。
このTodoアプリの機能要件は、利用者が入力したタスクをサーバで受け取りサーバで処理してなんらかのデータストアに永続保存できることとします。また既存のオフィス統合システムのAPIを呼び出し、本日のスケジュールを取得して表示する機能も必要です。
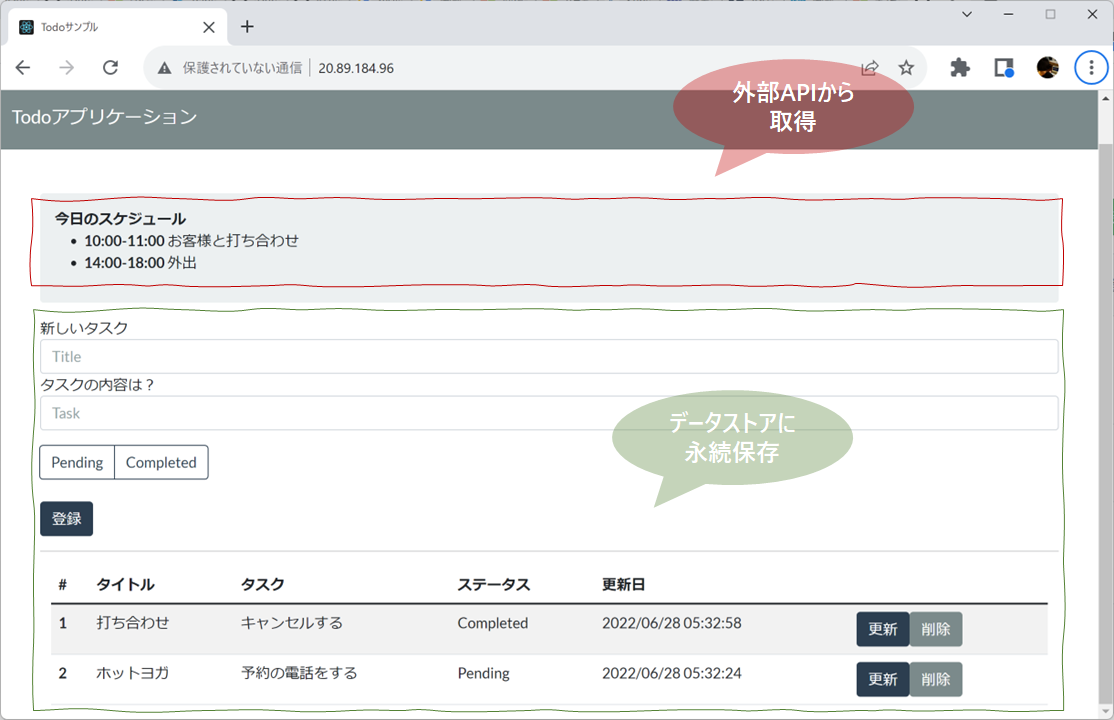
ただし、スケジュールを管理するシステムはSLAが低く、ネットワーク的にも遅延が発生します。しかしながらこのTodoアプリはミッションクリティカルな基幹業務システムで、もしこのシステムがダウンすると多大なる業務影響が発生します。また、お客様がクラウドの大規模システム障害とベンダーロックインを懸念されていて、可能であればマルチクラウドで動くシステムが望ましいという要件もあります。
Azureで動かす前提でアプリを作る場合
フロントエンドからバックエンドを呼び出し、データを分散データストアであるCosmos DBに保存し、同じくバックエンドから外部APIをコールしてスケジュールデータを取得して画面にデータを返せばよさそうです。バックエンドはコンテナ化して、Azure Kubernetes ServiceやAzure Container Appsなどでホストしてうごかせばよさそうです。フロントエンドはStatic Web Appsなども活用できそうです。
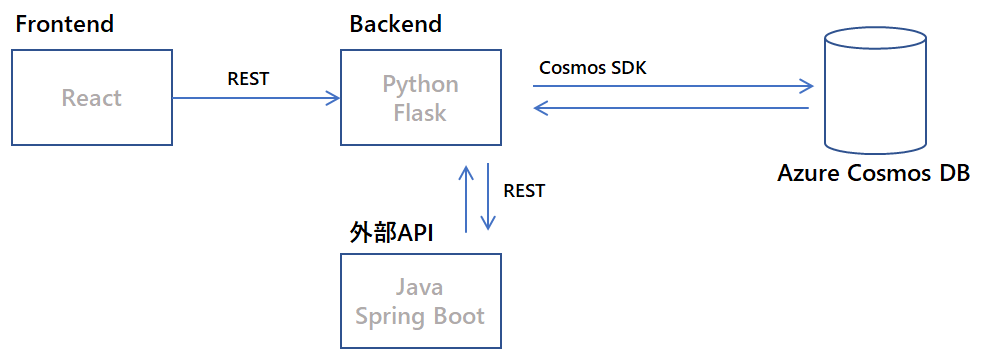
ただし、マルチクラウドで動くことを要件としてあげられているため、将来的にCosmos DBが別のデータストアになる可能性があります。その場合アプリケーションの改修が必要になります。
また、呼び出し先の外部APIはSLAが低いため一過性の障害が発生する可能性があります。そのため、アプリケーション側でリトライ処理/サーキットブレーカー等の考慮が必要です。
詳細については、以前に翔泳社のCodeZineで記事を書きましたので興味のある方はご覧ください。 Kubernetesでカオスエンジニアリング ~サーキットブレーカーパターンで回復性の高いシステムを構築する
Daprを使った分散アプリケーションの場合
上記の要件をアプリケーション目線で考えると
- 永続データを透過的に管理したい
- 外部サービス呼び出し時にミドルウエア的な処理を入れたい
ができれば開発者は楽ができそうです。これをアプリケーションランタイムで実現できるのがDaprです。
Daprは業務アプリケーションの横でサイドカーとして動きます。業務アプリケーションから永続データをデータストアに書き込む際/外部サービスを呼び出す場合は必ずDaprを経由します。その際、業務アプリケーションからDaprサイドカーへはHTTP/gRPCのいずれかでlocalhostとして通信します。そしてDaprサイドカー同士で通信してデータを保存したりサービスを呼び出したりします。
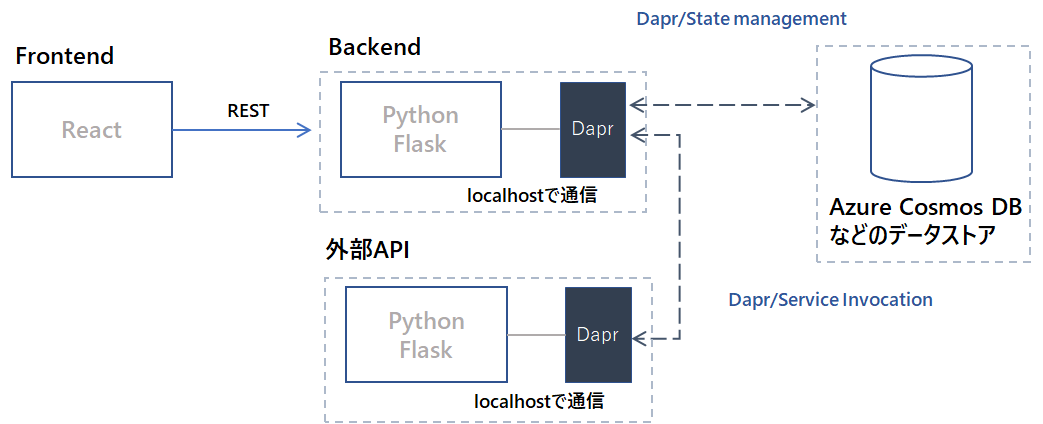
Daprにはリトライ処理やサーキットブレーカーなどの処理があらかじめ用意されています。そのためアプリケーション側で個別に実装するのではなく、Dapr側で吸収できます。
またDaprはマイクロソフトが積極的に開発を進めてはいるものの、パブリッククラウド/オンプレミス環境/ローカルの開発環境のいずれでも動作します。データの保存先のデータストアもAzure固有のサービスだけではありません。そのため将来的にAzure以外の環境に移行した場合も、少ない工数でアプリケーションの移植ができる可能性があります。
アプリケーションの開発
Daprアプリケーションを開発する際、いくつかのお作法があるのでそれを紹介します。(詳細はサンプルコードを見てください)
永続データの保存(State management)
Daprでは永続データの管理をState managementで行います。
まず、アプリがどのデータストアにアクセスするのかを定義するのに次のような定義ファイル(cosmosdb.yaml)を用意します。
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: cosmosdb # コンポーネントの名前/アプリ内から参照する
namespace: default
spec:
type: state.azure.cosmosdb # Azure Cosmos DBを使う場合
version: v1
metadata:
- name: url
value: https://xxx.documents.azure.com:443/ # Endpoint
- name: masterKey
value: xxxx # Cosmos DBへのアクセスキー
- name: database # Cosmos DBのデータベース名
value: db
- name: collection # Cosmos DBのコレクション名
value: test
Cosmos DB以外にもたくさんのState Storeが使えます。State Storeの対応状況と定義ファイルの書き方はこちらを参考にしてください。執筆時点(2020/06)でPostgre SQL/Readis/Mongo DBあたりがStableになってます。
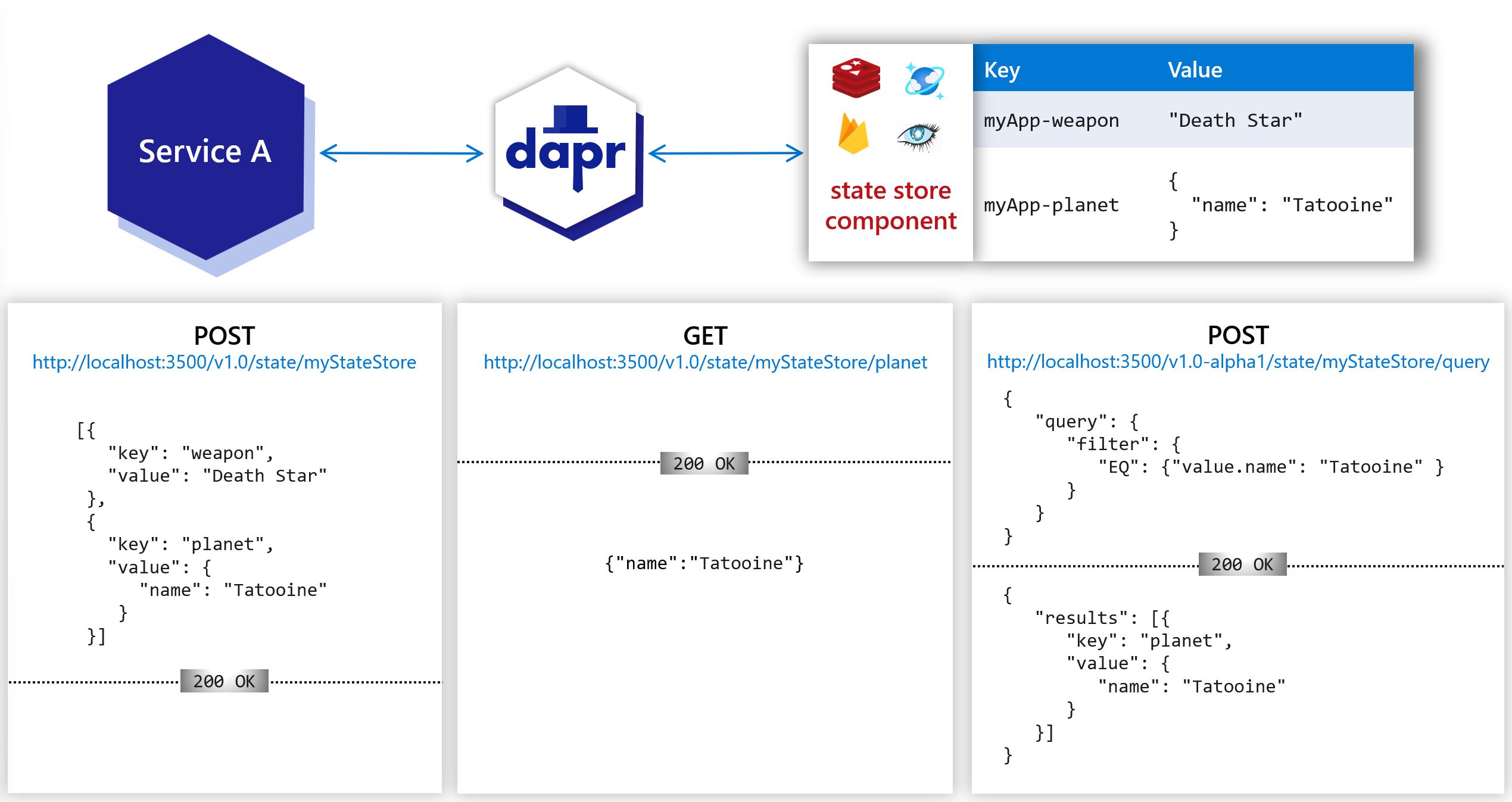
DaprのState managementはKey-Value型で管理しますが、この絵が分かりやすいです。
サービスからデータストアにアクセスするときは、以下のURLをCallします。ここでふと「本番環境でもエンドポイントはlocalhostでよいのかしら?」と思うかもしれませんが、大丈夫です。アプリ本体からみると自身のDaprサイドカーを呼び出すのだけなので、localhostのままです。
http://localhost:{Daprポート番号}/v1.0/state/{データストアの保存先(metadata.name)}"
Pythonで書くとこのようになります。変数state_store_nameは上記yamlで定義した、metadata.nameの値を指定します。今回は「cosmosdb」にしています。
ただRESTでリクエストを送信しているだけなので、どの言語でもほぼほぼ一緒です。
# Daprサイドカーのポート設定
dapr_port = os.getenv("DAPR_HTTP_PORT", 3500)
# Cosmos DB へのState 保存
state_store_name = "cosmosdb"
state_url = "http://localhost:{}/v1.0/state/{}".format(dapr_port, state_store_name)
...
# データ取得
@app.route('/api/v1/todos/<key>', methods=['GET'])
def get(key):
try:
response = requests.get(
state_url + "/" + key
)
return jsonify(json.loads(response.text)), status.HTTP_200_OK
except Exception as e:
return { "message": "Failed to get data" }, status.HTTP_500_INTERNAL_SERVER_ERROR
...
サービスの呼び出し(Service Invocation)
外部サービスの呼び出しはもっと簡単です。ヘッダーに { "dapr-app-id": "呼び出し先のサービスのDapr ID" }をつけて呼び出し先をCallするだけです。
今回は、外部APIを呼び出すサービスをscheduleとして動かします。
http://localhost:{Daprポート番号}/{呼び出し先のPath}"
# Schedule Service(Spring Boot)の呼び出し
schedule_url = "http://localhost:{}/schedule".format(dapr_port)
# スケジュール取得
@app.route('/api/v1/schedule', methods=['GET'])
def get_schedule():
try:
response = requests.get(
schedule_url,
headers = { "dapr-app-id": "schedule" }
)
data = json.loads(response.text)
...
except Exception as e:
return { "message": "Failed to get data" }, status.HTTP_500_INTERNAL_SERVER_ERROR
...
アプリケーションの実行
Daprアプリケーションはローカル環境でも動きますが、本番環境の場合はKubernetesで動かすのがなにかと便利です。
Kubernetesクラスタの作成
Kubernetesクラスタを用意します。ハードウエアを購入して物理ネットワークを敷設してMaster/Worker Nodeをセットアップするときっと楽しいでしょう。ただ、時間もお金もかかるのでクラウドベンダーが提供するマネージドサービスを利用するのが便利です。
Azureの場合、Azure Kubernetes Serviceを利用しチュートリアル通りに従えば10分程度でKubernetsクラスタが構築できます。
Daprのセットアップ
KubernetsクラスタにDaprのコンポーネントをデプロイします。手順は公式サイトにあるので特に迷う点はないはずです。
Daprをデプロイすると、dapr-systemというnamespaceが作成され必要なリソースが動いているのが分かります。
たとえば、dapr-sidecar-injectorはDaprがEnableなアプリに対してサイドカーを動かすデプロイメントであることがわかります。また、DaprがOperetorとして動作しているのもわかります。
$ k get ns
NAME STATUS AGE
dapr-system Active 11d
default Active 17d
kube-node-lease Active 17d
kube-public Active 17d
kube-system Active 17d
k get deploy,svc,statefulset -n dapr-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/dapr-api ClusterIP 10.0.232.2 <none> 80/TCP 11d
service/dapr-dashboard ClusterIP 10.0.214.75 <none> 8080/TCP 11d
service/dapr-placement-server ClusterIP None <none> 50005/TCP,8201/TCP 11d
service/dapr-sentry ClusterIP 10.0.140.191 <none> 80/TCP 11d
service/dapr-sidecar-injector ClusterIP 10.0.111.209 <none> 443/TCP 11d
service/dapr-webhook ClusterIP 10.0.2.156 <none> 443/TCP 11d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/dapr-dashboard 1/1 1 1 11d
deployment.apps/dapr-operator 1/1 1 1 11d
deployment.apps/dapr-sentry 1/1 1 1 11d
deployment.apps/dapr-sidecar-injector 1/1 1 1 11d
NAME READY AGE
statefulset.apps/dapr-placement-server 1/1 11d
Cosmos DBのState Storeコンポーネントのデプロイ
上記で作成したCosmos DBのState Store(cosmos.yaml)をデプロイします。
k apply -f path-to-manifest/cosmosdb.yaml
次のコマンドでState Storeのコンポーネントを確認できます。
k get component
NAME AGE
cosmosdb 6h31m
アプリケーションのデプロイ
Daprアプリケーションも通常のKubernetesアプリケーションと同様マニフェストファイルを用意します。記述のしかたはほぼ一緒ですが、Daprアプリケーションを識別するためのアノテーションを設定します。必要な設定は次のとおりです。
| annotations | value | 説明 |
|---|---|---|
| dapr.io/enabled | true | Daprを有効にするかどうか |
| dapr.io/app-id | backend | Dapr ID(クラスタ内で一意になるように設定) |
| dapr.io/app-port | 8080 | ポート番号 |
| dapr.io/config | featureconfig | Configファイルを読み込む |
dapr.io/configアノテーションは、Daprでリトライ処理などを行うために必要な設定です(詳細は後述)
例えば、Backendアプリのマニフェストファイルはこのような感じになります。
kind: Deployment
apiVersion: apps/v1
metadata:
name: backend
...
spec:
...
template:
metadata:
...
annotations:
dapr.io/enabled: "true"
dapr.io/app-id: "backend"
dapr.io/app-port: "8080"
dapr.io/config: "featureconfig"
spec:
containers:
次のコマンドを実行してアプリケーションをクラスタにデプロイします。
k apply -f path-to-manifest/backend.yaml
同様に、外部API呼び出し先のshceduleアプリケーションのマニフェストファイルも作成し、アプリケーションをクラスタにデプロイします。
kind: Deployment
apiVersion: apps/v1
metadata:
name: schedule
...
spec:
...
template:
...
annotations:
dapr.io/enabled: "true"
dapr.io/app-id: "schedule"
dapr.io/app-port: "8083"
dapr.io/config: "featureconfig"
spec:
containers:
k apply -f path-to-manifest/schedule.yaml
ついでにフロントエンドアプリもデプロイしておきましょう。
k get po
NAME READY STATUS RESTARTS AGE
backend-7989b84656-25hq4 2/2 Running 0 5h50m
frontend-6c5f759f6-hn6pk 1/1 Running 0 5h44m
schedule-dd66d67bc-7svvh 2/2 Running 0 5h50m
Podを確認すると、DaprをEnableにしたbackendとscheduleにはDaprのサイドカーであるdaprdがInjectされているのが分かります。そして、コマンド引数でDaprのポート番号はじめDapr Control Planeにアクセスするのに必要な情報がセットされているのがわかります。
$ k describe po backend-7989b84656-25hq4
Name: backend-7989b84656-25hq4
Namespace: default
...
Annotations: dapr.io/app-id: backend
dapr.io/app-port: 8080
dapr.io/config: featureconfig
dapr.io/enabled: true
Status: Running
...
Containers:
backend:
Container ID: containerd://
...
daprd:
Container ID: containerd://
Ports: 3500/TCP, 50001/TCP, 50002/TCP, 9090/TCP
Host Ports: 0/TCP, 0/TCP, 0/TCP, 0/TCP
Command:
/daprd
Args:
--mode
kubernetes
--dapr-http-port
3500
--dapr-grpc-port
50001
--dapr-internal-grpc-port
50002
--dapr-listen-addresses
[::1],127.0.0.1
--dapr-public-port
3501
--app-port
8080
--app-id
backend
--control-plane-address
dapr-api.dapr-system.svc.cluster.local:80
--app-protocol
http
--placement-host-address
dapr-placement-server.dapr-system.svc.cluster.local:50005
...
動作確認
ここまでの状態で、ブラウザからfrontendアプリのService Endpointにアクセスすると約50%の割合で「スケジュールデータが取得できません」という悲しいエラーが出ます。
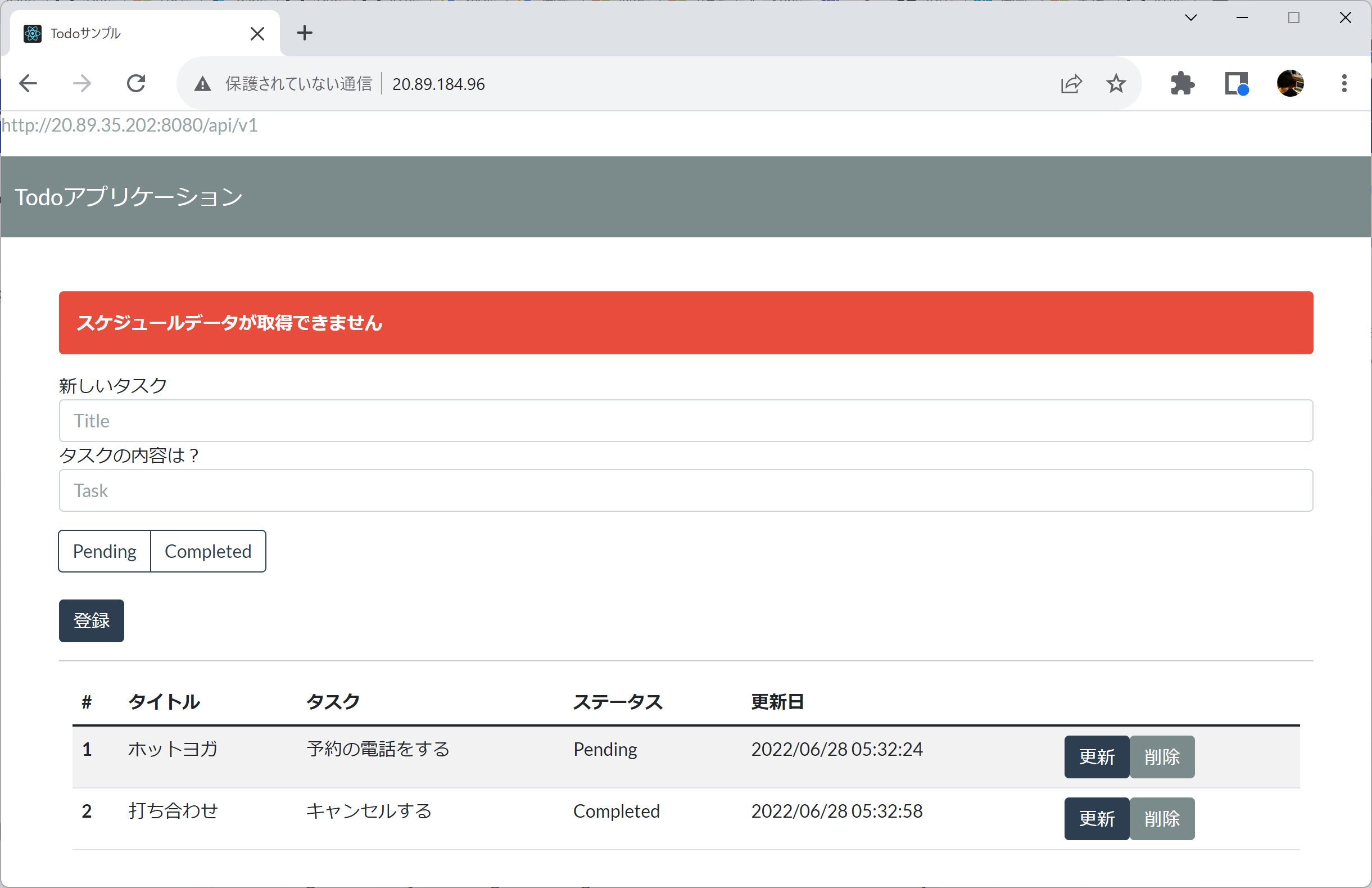
なぜかというと、backendアプリからDapr経由で呼び出されるscheduleアプリは50%の確率で500エラーを返すようわざと実装しているためです。
いやいやいくらなんでも、2回に1回失敗するAPIとか現実世界では無いだろ、、、という気もしますが、クラウドサービスの多くはSLAが99.95%~に設定されています。これは裏を返せば1000回リクエストを送ると5回ぐらいはエラーになる..かもね…ということを意味していて、一過性の障害が完全に無いと言い切れるものではありません。
Daprによるリトライ/サーキットブレーカー
一過性の障害が発生したとしても、すこし待ってリトライすれば業務影響を減らせるかもしれません。Daprにはアプリケーションの回復性を持たせる機能が提供されています。試してみましょう!
これを利用するには、Preview featuresを有効にする必要があります。次の内容でconfig.yamlを作成して、Kubernetesクラスタにデプロイします。
apiVersion: dapr.io/v1alpha1
kind: Configuration
metadata:
name: featureconfig
spec:
features:
- name: Resiliency
enabled: true
k apply -f path-to-manifest/config.yaml
そしてPreview featuresを有効にしたいDeploymentのアノテーションにdapr.io/configが設定されていることを確認します。※:すでに設定済みです
次に、リトライやサーキットブレーカーのポリシーresiliency.yamlを定義します。分かりにくいところはコメントを入れましたが、ポイントとしては、Dapr IDごとにScopeを設定でき、どのスコープ(=Daprアプリ)に対して、どのようなポリシーを割り当てるかを設定できるところになります。
Kubernets RBACの設定的なものをイメージしてもらえば理解しやすいと思います。
apiVersion: dapr.io/v1alpha1
kind: Resiliency
metadata:
name: todo-resiliency
# Resiliency spec が使用できる Dapr App ID
scopes:
- schedule
- backend
spec:
# policies は、タイムアウト、再試行、サーキットブレーカーポリシーを定義する場所
# それぞれ名前がついており、resiliency-specのtargetsから参照できる
policies:
# タイムアウトの設定
timeouts:
general: 5s
important: 60s
largeResponse: 10s
# リトライの設定
retries:
pubsubRetry:
policy: constant
duration: 5s
maxRetries: 10
retryForever:
policy: exponential
maxInterval: 15s
maxRetries: -1 # retry indefinitely
important:
policy: constant
duration: 5s
maxRetries: 30
someOperation:
policy: exponential
maxInterval: 15s
largeResponse:
policy: constant
duration: 5s
maxRetries: 3
# サーキットブレーカーの設定
# サーキットブレーカーは、Daprサイドカーが動作している限り、カウンターを維持しますが永続化されません。
circuitBreakers:
simpleCB:
maxRequests: 1
timeout: 30s
trip: consecutiveFailures >= 5
pubsubCB:
maxRequests: 1
interval: 8s
timeout: 45s
trip: consecutiveFailures > 8
# Dapr はapps/components/actorsの3つのターゲットタイプをサポート
targets:
# Dapr appsに対する設定
apps:
schedule: # Dapr IDを設定
timeout: general
retry: retryForever
circuitBreaker: simpleCB
components:
# Dapr Stateに対する設定
cosmosdb: # StateStore名を設定
outbound:
timeout: general
retry: retryForever
ここでは、scheduleに対してretryForeverのルール、つまりExponential Backoffで無限にリトライを続け、サーキットブレーカーとしてsimpleCBのルール、つまりタイムアウト30sでサーキットブレイクさせるという設定を入れています。
同様にデータストアであるCosmos DBに対してはretryForeverのルールで再送しています。
次のコマンドでマニフェストファイルをデプロイします。
k apply -f path-to-manifest/resiliency.yaml
再度frontendにリクエストを複数回送ってみましょう。めでたしめでたしとなっているはずです。
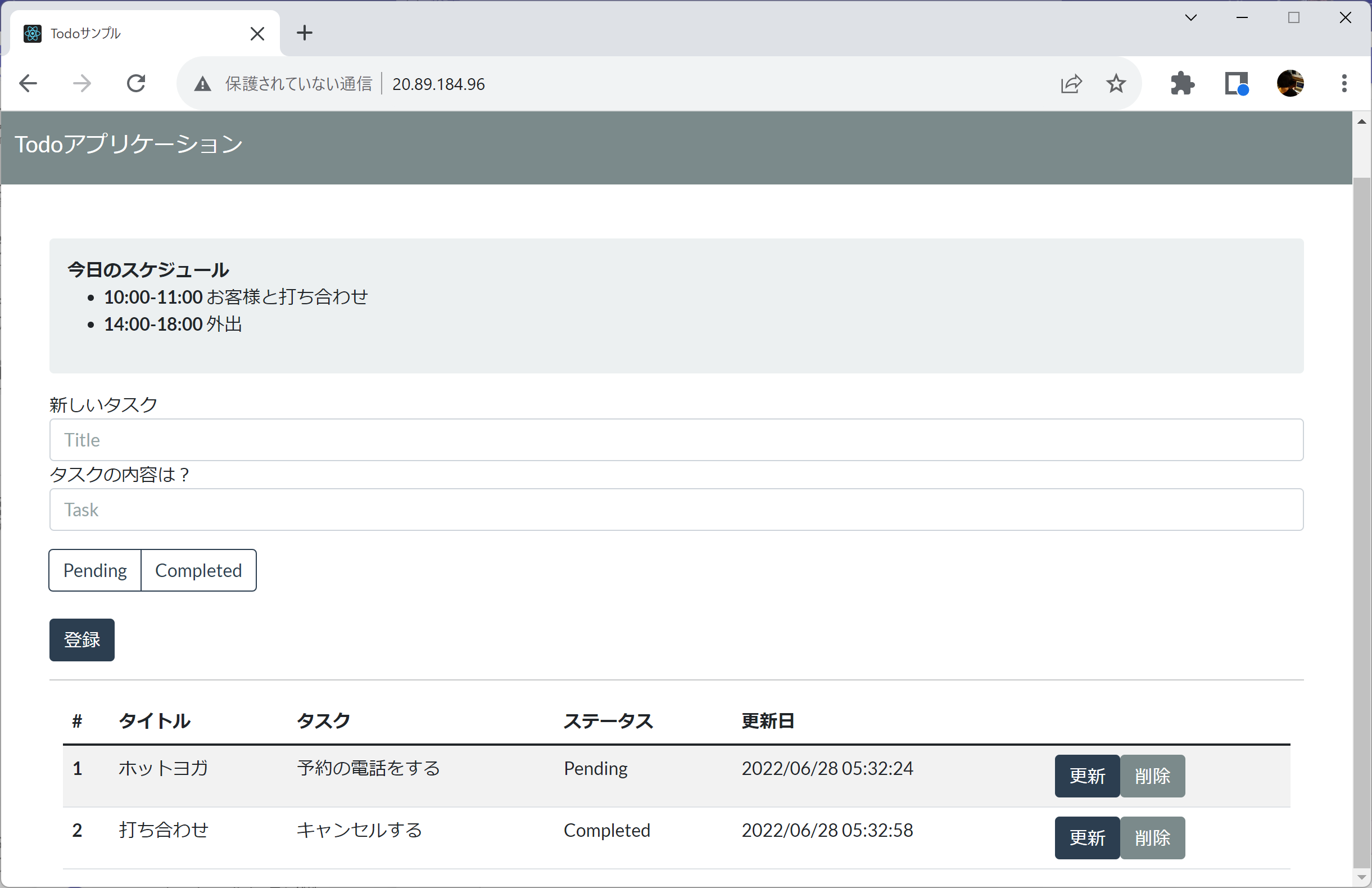
これで、開発者の要望である
- 永続データを透過的に管理したい
- 外部サービス呼び出し時にミドルウエア的な処理を入れたい
はDaprによってある程度実現できることが分かりました。Daprをうまく活用することで、お客様の要件にあった「マルチクラウドでも動くアプリケーションが欲しい」「分散システムの一過性の障害でも業務を止めないシステムが欲しい」に一歩近づけることができるかもしれません。
(どう実装されている?)
ここからは完全に余談ですが、どういうResiliencyが実装になっているのか少し気になったのでしらべてみたのですが、Golangで実装されているDapr State Store/Cosmos DBのExponential backoffはcenkalti/backoff/v4が使われているようです。
また、Service Invokeについては、invokeWithRetryで実装されています。
Daprにかぎらずリトライ処理をミドルレイヤーで行うのは一長一短あるので、中でどういう動きをするのかをきちんと押さえておかないと、本番環境で障害が発生したときに大変な目にあうので要注意です。
(課題) Azure Containe AppsでDaprをサポート!が、しかし…..
2022のBuildで人類待望の「Azure Containe Apps」が一般提供されました。
Azure Containe Appsの大きな特徴として、
- Kubernetsをベースにしたコンテナのマネージドな実行環境
- No opinionated programming model
- KEDA/Envoy/Dapr/Virtual KubeletなどCNCFプロジェクトを多数取り込んでいる
- GitHub Actons連携
などがあげられます。なにより、Kubernets APIにアクセスしなくてもKubernets環境上でよしなにやってくれるというのは、多くの開発者にとっては嬉しいことです。
個人的には、Azureの新規案件でコンテナワークロードを動かすものに関しては、ほぼこれを選んでおけば大丈夫なのでは? と思っています。
このAzure Containe AppsはDaprをネイティブでサポートしていて、このようなコマンドを実行するだけでDaprサイドカーをInjectできます。便利!
az containerapp create \
...
--enable-dapr \
--dapr-app-port 8080 \
--dapr-app-id backend
Azure Containe Appsすごく良い!!のですが、執筆時点(2022/06/28)でDaprまわりでいくつかできないことがあることが分かったのでまとめておきます。
State management APIでQuery stateが使えない
State management APIのQuery stateは現在Alpha Stageであるため、リクエストURLを以下のようにv1.0-alpha1にする必要があります。AKSにデプロイした場合はAlpha Stage APIでも利用できますが、これがContainer Appsでは動作しません。
POST/PUT http://localhost:<daprPort>/v1.0-alpha1/state/<storename>/query
これが利用できないと、たとえばCosmos DBでデータをクエリし必要な値をfilterして取り出せません。 ※ issue #155でも議論されています。
Daprのpreview featureが使えない
普段日本語で公式ドキュメントを読んでいる弱者なので翻訳の違和感にまったく気づかず、かれこれ2日間ぐらいハマってしまったのですが、あらためて英語の原文のマニュアルUnsupported Dapr capabilitiesをきちんと読むと
Dapr Configuration spec: Any capabilities that require use of the Dapr configuration spec.
とあります。
本記事ではDaprのResiliencyについて紹介しましたが、このResiliencyはpreview featureのため、Dapr Configuration specを変更する必要があります。KubernetsでセルフホストでDaprをセットアップした場合はこの値を書き換えて構成することができますが、マネージドサービスであるAzure Containe Appsの場合はこれができません。
つまり、Container Appsでは現時点でリトライ処理やサーキットブレーカー始め、Daprのpreview featureを試せません。
まとめ
Daprを使うと回復性・耐障害性の高いシステムをアプリケーションレベルで実装できる可能性がある、というのが分かりました。
Daprにはいろいろな機能があって、ごく一部しか追いかけられていないですが、今後も大注目のテクノロジーです。
つづく